
SBI証券のレイアウトが難しい。というか分からない。
毎回迷う。
何年たっても改善されない。別の証券会社に移行したい。
2025-05-21 My資産という項目が追加されていたようなので。
https://site.sbisec.co.jp/account/assets
ここら辺で見える。
かなりグラフィカルで見やすくなった気がする。
配当金額とかもまとまっているし。
しかしなぁ。旧レイアウトと混合していたり、世界の大手と比べるとなんでこんななんだって位の使い勝手ではあるんだが。
2024-08-15 米ドルMMFを直接買い付け資金にできないが自動再投資はできるのでその設定をしておきました。
この辺は楽天証券のほうがいいよね。米ドルMMFを直接米国株の買い付けに設定できたと思うし。
とりあえず自動再投資はこれでいいのかなと。
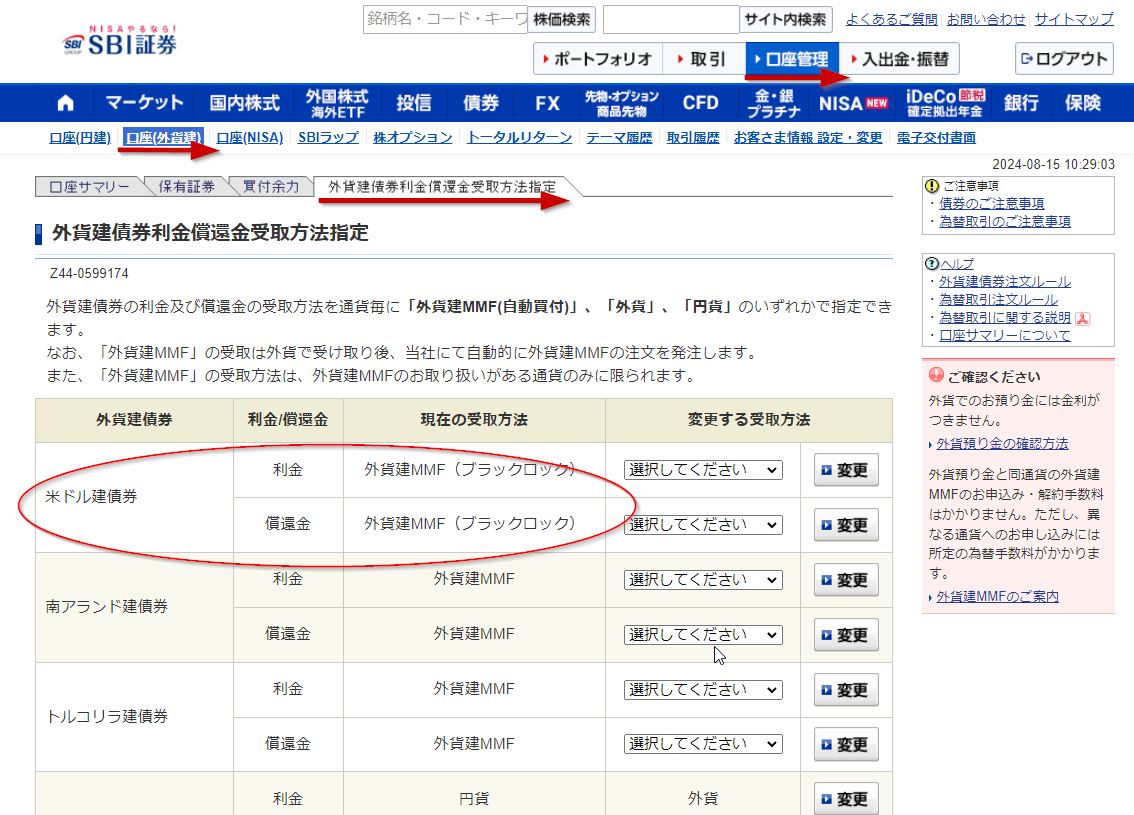
2024-08-14 外貨建てMMFの注文履歴の照会。どこにあるのか毎回忘れるので。
解説はこちらにあった。
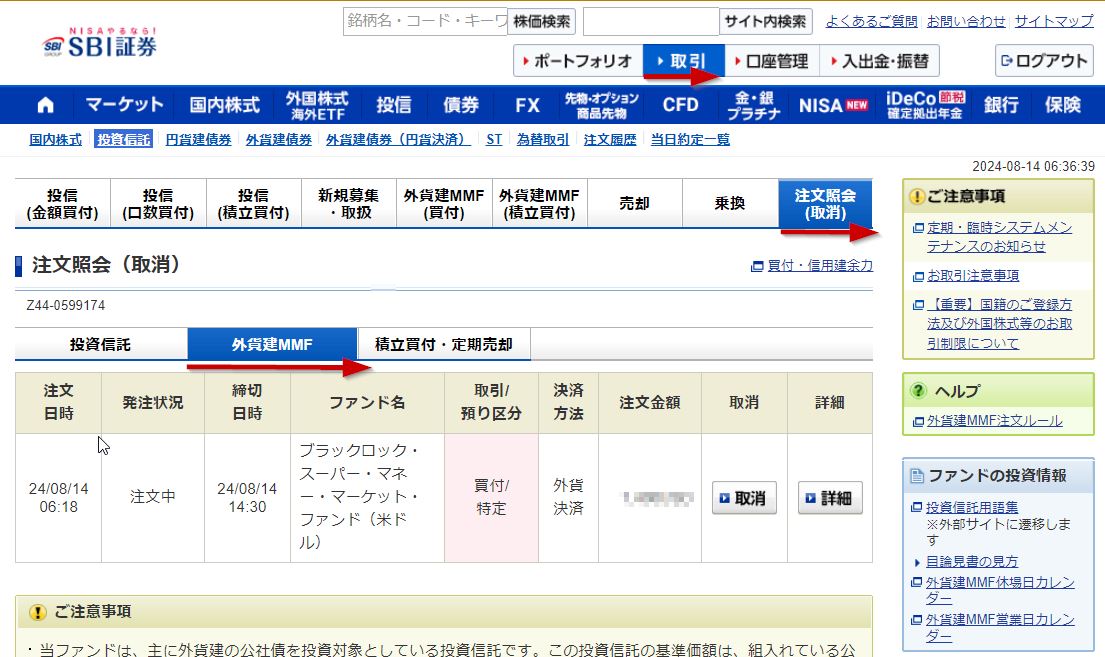
2024-07-25 注文出した後にメンテナンスって画面が出るの何とかならんのかね。
注文出す前からわかるでしょうよ。
数量とか保管口座とか選択してパスワード入力してSubmitしてから出てこなくてもいいじゃん。

それにこの画面が出るなら出たで、いつまでメンテナンス中ってダイレクトに出してくれればいいのに。
「あなたの注文方法は何時までメンテンナンスです」 とかさ。
あまりにも何回も同じ画面を見るんだよね。
2024-07-02 外貨建て銘柄の約定履歴。やっぱりCSVから見たほうが簡単だったので。
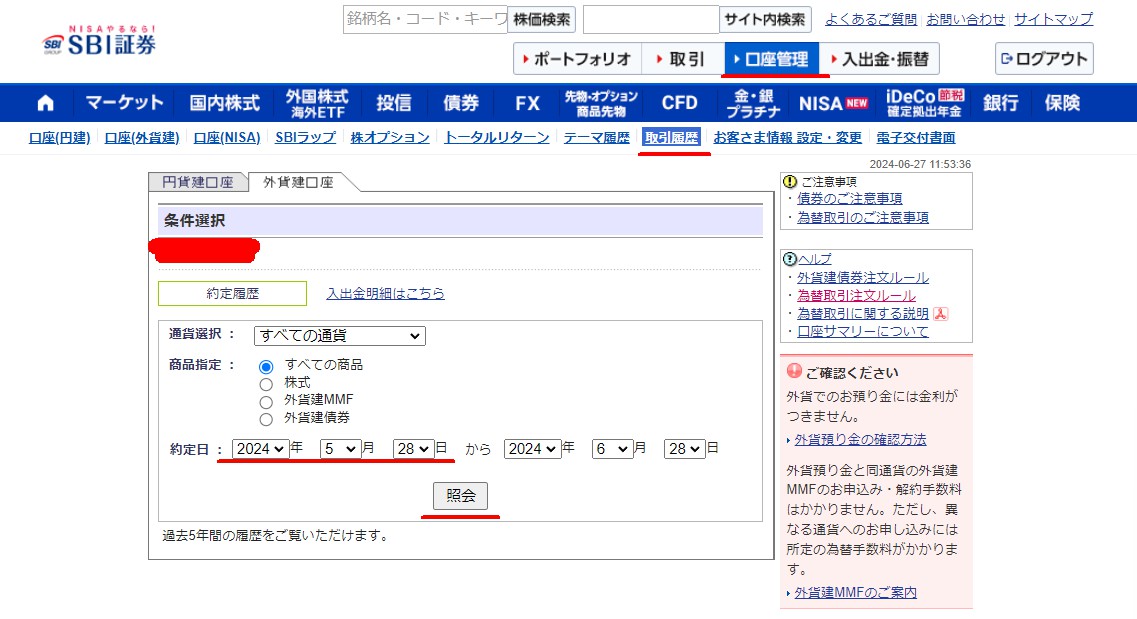
Webの画面上からだとフィルター機能がないのか?
仕方ないなぁ。
見出しを削除してフィルタを適用したところ。
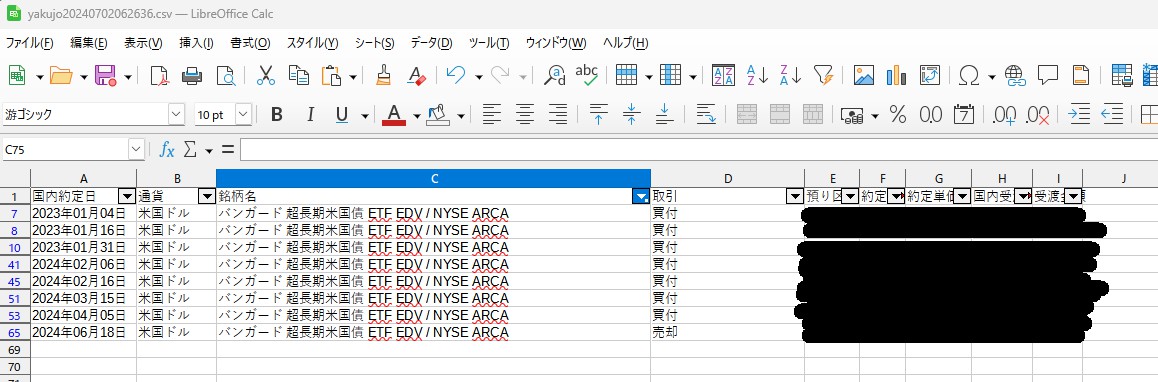
Libreoffice >> 上2行削除 >> 全選択 >> データ(D) >> オートフィルター >> ドロップダウン(Cカラム) >> 項目を検索(テキスト入力 >>>> ”すべて(B)”のチェックを外す >> 対象項目のチェックを入れる
2024-07-01 配当履歴がどこで見れるかメモ
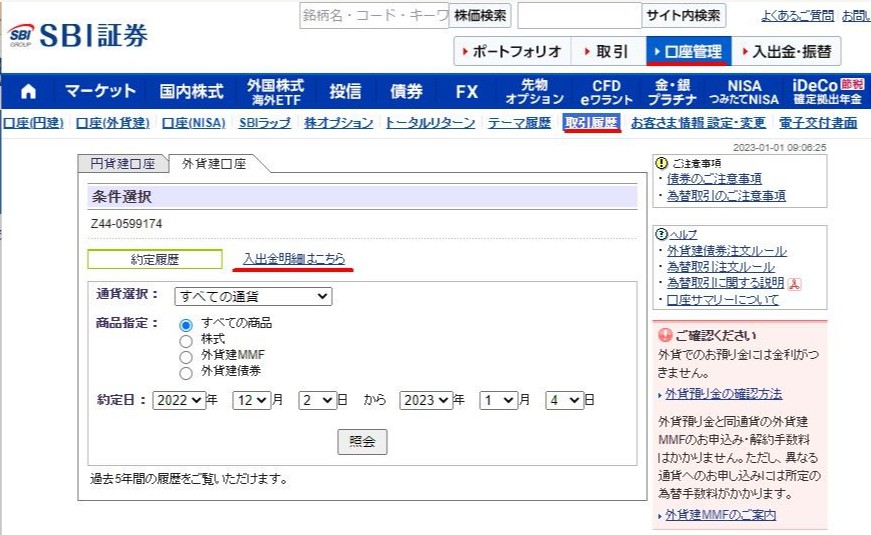
2024-06-27 外貨建ての約定履歴がポートフォリオからではわからないのに対応
結局ここから検索して、Ctrl+F で銘柄で検索するしかないのかも。
CSVも落とせるけど、それはそれで面倒くさいでしょうよ。
2024-06-04 外貨入手 定時約定通貨 ベトナムドン
ベトナムドンは定時為替取引で入手できるよって説明はあった。
じゃあ手続きはここからってリンクしてくれればいいのにな。
探し回ってしまったよ。
どうせまた忘れそうなのでメモ。
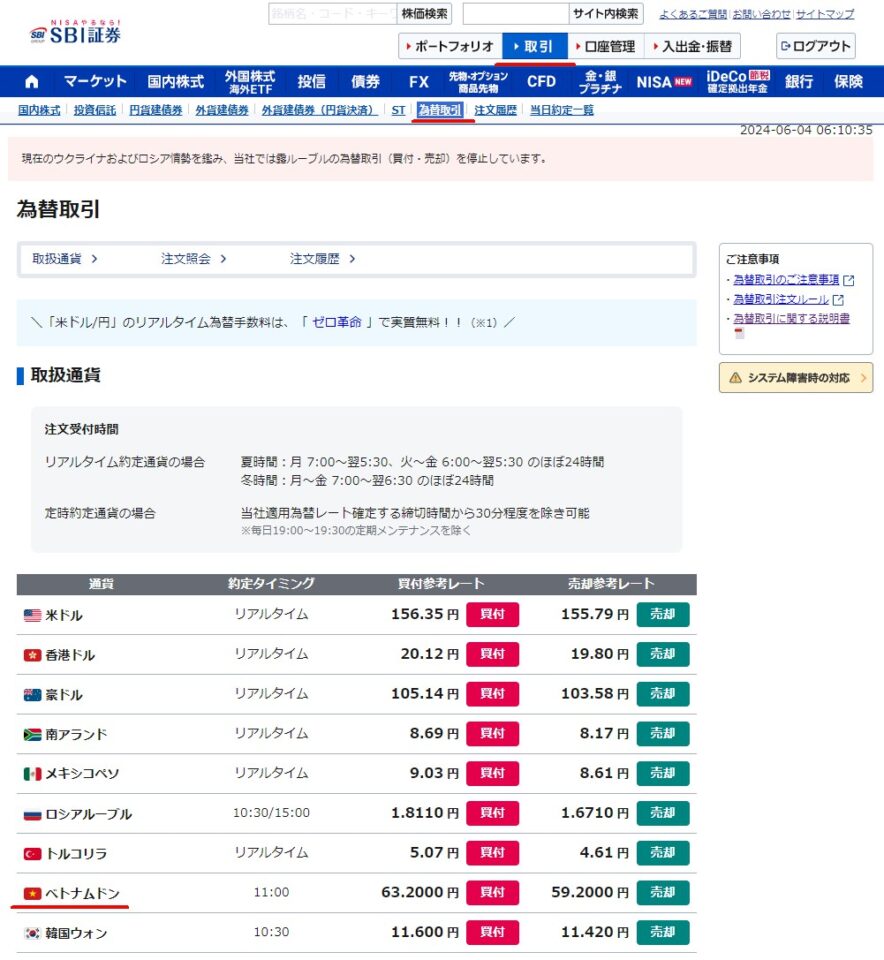
損益とか計算する必要あると面倒なので、ベトナム株買い付け金額分ちょうどだけ変換すると思う。
2024-05-13、円建て。どの銘柄をいくら持っている?
かなり基本的なはずだが、「ポートフォリオ」からだと資産ごとのレイアウトが違う。
「ポートフォリオ」のCSVダウンロードすると投資信託分が不明?
口座管理
![]()
「保有資産評価」セクションの「投資信託」の合計はどの項目の合計なのか?

詳細をクリック。
とんだ先のページにあるCSVをダウンロード

その中の評価額を合計したら、「投資信託」の金額とマッチした。
NISA、特定、両方の内訳を全部足すとマッチする。
やばい。わかりづらい。
トータル金額を表示して、ネストして銘柄ごと、更にネストして、買付日ごとに金額を表示してほしい。
JSとか使ってできるよね。というか普通そうしないか?
かなりやばいUIだと思う。
一応ダウンロードできたCSVで円建てであれば銘柄名ごとのポジション、評価額などがわかる。
外貨建て口座の保有銘柄ごとのCSVはないの?
本当にないのか?
色々調べたけど今のところ見つかっていない。
私の探し方が悪いのかもしれないけど、あるなら教えてほしい。
今のところHTMLしか見つけられていないので、これをCSVに変換するか?
本当に?でもCSVほしいよね。だって、表計算で使えねーんだもん。
仕方ないからスクリプトを作りました。python.
import pandas as pd
from bs4 import BeautifulSoup
import argparse
import os
# コマンドライン引数の設定
parser = argparse.ArgumentParser(description='Convert HTML tables to CSV files.')
parser.add_argument('--single-file', action='store_true', help='Combine all tables into a single CSV file.')
args = parser.parse_args()
# HTMLファイルのパス
html_file_path = './sbi.html'
# HTMLファイルを読み込む
with open(html_file_path, 'r', encoding='utf-8') as file:
html_content = file.read()
# BeautifulSoupを使ってHTMLを解析する
soup = BeautifulSoup(html_content, 'html.parser')
# 関数:カラムの分割処理
def split_columns(header_row, data_rows):
expanded_header = []
expanded_data = []
for col_index, item in enumerate(header_row):
max_splits = max((len(row[col_index].split('|br|')) if col_index < len(row) else 1) for row in data_rows) if data_rows else 1
# ヘッダーを分割
parts = item.split('|br|')
expanded_header.extend(parts + [''] * (max_splits - len(parts)))
# データを分割
for row_index, row in enumerate(data_rows):
if len(expanded_data) <= row_index:
expanded_data.append([])
data_parts = row[col_index].split('|br|') if col_index < len(row) else ['']
expanded_data[row_index].extend(data_parts + [''] * (max_splits - len(data_parts)))
return expanded_header, expanded_data
# 関数:テーブルを処理してCSVファイルに保存
def process_table(table, table_index, single_file=False):
# 初期データフレームの作成
rows = table.find_all('tr')
data = []
for row in rows:
cells = row.find_all(['td', 'th'])
row_data = []
for cell in cells:
# `
` を明示的に "|br|" として扱う
html_text = str(cell)
cleaned_text = html_text.replace('
', '|br|').replace('
', '|br|')
text = ' '.join(BeautifulSoup(cleaned_text, 'html.parser').get_text(separator=" ").split())
row_data.append(text)
data.append(row_data)
if not data:
return None, None
# 見出し行とデータ行に分割
header_row = data[0]
data_rows = data[1:] if len(data) > 1 else []
# 見出し行とデータ行を分割処理
columns, expanded_data = split_columns(header_row, data_rows)
# 列数を最大長に合わせる
max_cols = max(len(columns), max((len(row) for row in expanded_data), default=0))
columns.extend([''] * (max_cols - len(columns)))
for row in expanded_data:
row.extend([''] * (max_cols - len(row)))
# 最終的なデータフレームを作成
if expanded_data:
df_final = pd.DataFrame(expanded_data, columns=columns)
else:
df_final = pd.DataFrame(columns=columns)
if not single_file:
# CSVファイルへの保存
csv_file_path = f'final_output_with_br_expanded_table_{table_index}.csv'
df_final.to_csv(csv_file_path, index=False, encoding='utf-8')
print(f'拡張されたCSVファイルが {csv_file_path} に保存されました。')
return columns, expanded_data
# 全てのテーブルを処理
tables = soup.find_all('table')
all_data = []
for table_index, table in enumerate(tables):
columns, expanded_data = process_table(table, table_index, single_file=args.single_file)
if columns and expanded_data:
if all_data:
# 前のテーブルと区別するために空行を追加
all_data.append([''] * len(columns))
all_data.append(columns)
all_data.extend(expanded_data)
if args.single_file and all_data:
# 最終的なデータフレームを作成
max_cols = max(len(row) for row in all_data)
for row in all_data:
row.extend([''] * (max_cols - len(row)))
df_final = pd.DataFrame(all_data[1:], columns=all_data[0])
# 1つのCSVファイルに保存
csv_file_path = 'final_output_with_br_expanded_all_tables.csv'
df_final.to_csv(csv_file_path, index=False, encoding='utf-8')
print(f'全てのテーブルが1つのCSVファイルに {csv_file_path} に保存されました。')
・実行は以下。
D:\temp>python convert1.py --single-file
のように実行する。
カレントディレクトリの、”sbi.html”を認識して、CSVに変換する。
–single-file オプションがなければ複数CSVファイルを作る。
元データはSBIにログイン後、口座管理、口座(外貨建)、保有証券
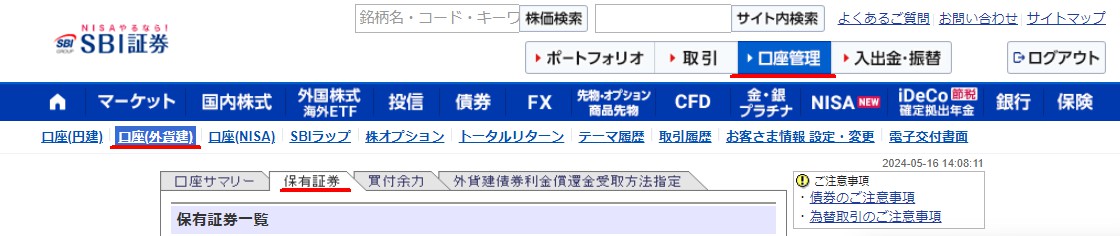
ページのソースを表示。これを、”sbi.html” としていったん保存している。
個人的には”米国株式(特定預り)”より上のデータは必要ないので削除。
”参考為替レート”も必要ないのでこれより下も削除。
テーブルを認識するので、”sbi.html” の最初と最後はこんな感じで作っている。
これでいろいろ計算に使えるデータになったかな?
![]()